Last week I wrote a post about Streamlit as a result of a Python Essentials training. I really liked the training so it inspired me to try some things out.
Recently I was working on a sample database I can use in several examples working with Snowflake. On Kaggle I found the; ‘Formula 1 World Championship’ dataset with F1 race data from 1950 to 2021. Of course there are several ways to load this data into Snowflake. This time it made sense for me to do it using Python 🐍. Python is probably not the most obvious solution, but (as a Python newbee) interesting enough for me to work out.
The solution is based on the following components:
- .csv’s with the F1 race data
- Snowflake Python Connector
- Panda’s
Setting the environment
First I had to download the Kaggle-dataset and store the files locally. From within the Python-script I point to this location.
file_location = '<Local file location>'
Also I had to make the connection to Snowflake. To make this happen I created a similar setup as in my previous post:
# Setting up Snowflake connection
conn_location = '<Credential file location>'
connect = json.loads(open(str(conn_location+'/<Credential file>')).read())
username = connect['secrets']['username']
password = connect['secrets']['password']
account = connect['secrets']['account']
role = connect['secrets']['role']
# Connect to Snowflake
conn = snowflake.connector.connect(
user = username,
password = password,
account = account,
role = role
)Reading .csv Data
WIth the glob-library I was able to browse the file location where I downloaded the .csv-files.
f1_demo_files = glob.glob(file_location + "/*.csv")
Now I can loop through the directory and handle the separate files one by one.
for file in f1_demo_files:Creating Snowflake objects
For each file I find in the directory, I can create a table.
# Getting filename in UPPERCASE and removing .csv
filename = os.path.splitext(os.path.basename(file))[0].upper()
f1_pre_table = 'PRE_F1PY_' + filename
# Create a CREATE TABLE SQL-statement
create_tbl_sql = "CREATE TABLE IF NOT EXISTS " + demo_db + "." + f1_pre_schema + "." + f1_pre_table + " (\n"
A Pandas Data Frame helps me selecting the columns from the file.# Making a data frame to read the columns from
dfF1 = pd.read_csv(file)Looping through the columns helps me completing the ‘CREATE TABLE’-statement.
# Iterating trough the columns
for col in dfF1.columns:
column_name = col.upper()
if (dfF1[col].dtype.name == "int" or dfF1[col].dtype.name == "int64"):
create_tbl_sql = create_tbl_sql + column_name + " int"
elif dfF1[col].dtype.name == "object":
create_tbl_sql = create_tbl_sql + column_name + " varchar(16777216)"
elif dfF1[col].dtype.name == "datetime64[ns]":
create_tbl_sql = create_tbl_sql + column_name + " datetime"
elif dfF1[col].dtype.name == "float64":
create_tbl_sql = create_tbl_sql + column_name + " float8"
elif dfF1[col].dtype.name == "bool":
create_tbl_sql = create_tbl_sql + column_name + " boolean"
else:
create_tbl_sql = create_tbl_sql + column_name + " varchar(16777216)"
# Deciding next steps. Either column is not the last column (add comma) else end create_tbl_statement
if dfF1[col].name != dfF1.columns[-1]:
create_tbl_sql = create_tbl_sql + ",\n"
else:
create_tbl_sql = create_tbl_sql + ")"Finally I can execute the statement
#Execute the SQL statement to create the table
conn.cursor().execute(create_tbl_sql)
Loading Data into Snowflake
Snowflake is ready to load data into using write_pandas.
# Write the data from the DataFrame to the f1_pre_table.
write_pandas(
conn=conn,
df=dfF1,
table_name=f1_pre_table,
database=demo_db,
schema=f1_pre_schema
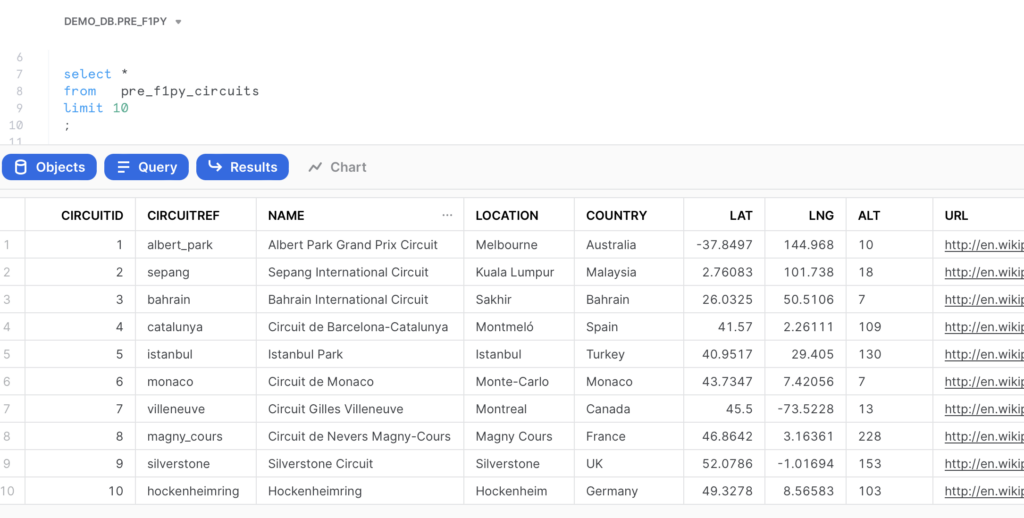
) The ‘Formula 1 World Championship’ dataset is ready to be used in Snowflake in consecutive examples.
Find the code for this blogpost on Github.
Thanks for reading and till next time.